
Wat is de uitdaging?
De uitdaging is om bepaalde informatie uit documenten te halen en deze op te slaan in een database voor andere toepassingen.
Wat heb je nodig?
We hebben een aantal zaken nodig:
- Een voorbeeld document;
- Klippa DocHorizon;
- Promptbuilder;
- Lowcode server.
Met deze oplossing kun je zonder problemen in batch documenten herkennen en via JSON opslaan in bijvoorbeeld MYSQL.
Een voorbeelddocument
Ik ben net terug van vakantie en was nog in het bezit van een slechte kopie van het autohuur contract. Ik dacht, mooie uitdaging voor Klippa.

Zoals je kunt zien is dit document behoorlijk onleesbaar voor een mens, althans, voor mij 🙂
De promptbuilder
Via de promptbuilder van DocHorizon kun je via een normale vraagstelling informatie uit het document halen. Bijvoorbeeld: Wat is de kleur van de auto?
Hieronder zie je een aantal vragen die ik gesteld heb.
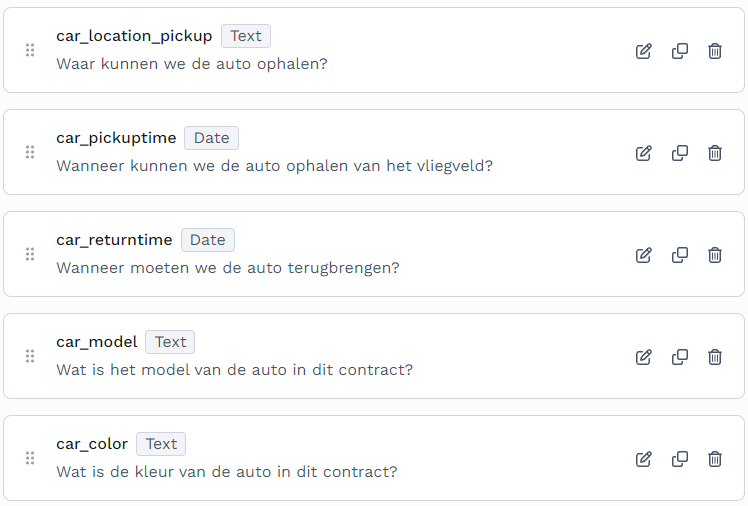
Het is echt verbluffend om te zien hoe dit werkt. Dit is voor een mens een slecht leesbaar contract maar de AI van DocHorizon heeft er weinig moeite mee.
Het bouwen van het datamodel
Wat we feitelijk aan het doen zijn is een datamodel bouwen van het document. Alle informatie die we nodig hebben ik straks beschikbaar in JSON formaat via een API. Hieronder zie je een voorbeeld van het veld wat we hebben aangemaakt.
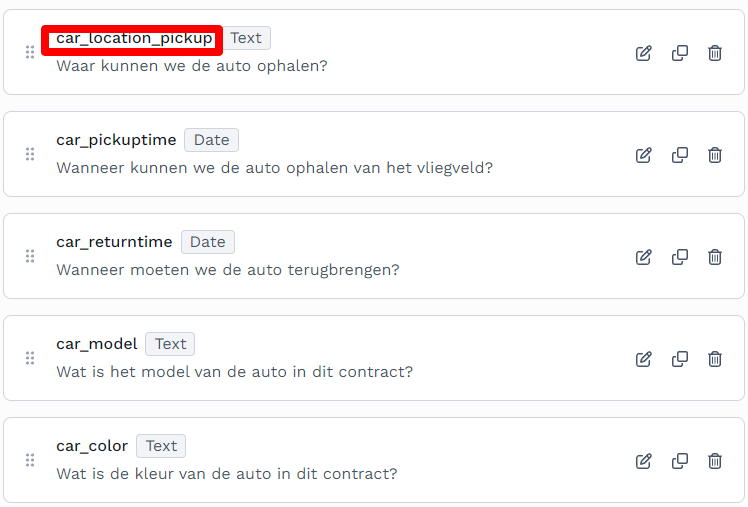
Als je alle velden hebt aangemaakt dan kun je met de Preview optie kijken welke informatie er uit het document gehaald kan worden.
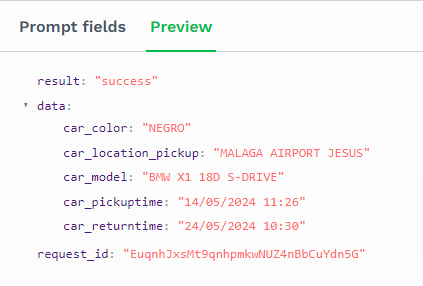
Omdat het een Spaans document is krijgen we kleur in het Spaan, negro. Wat ik nog mis in DocHorizon is een optie om dit automatisch te laten vertalen.
We zijn nu klaar met de promptbuilder. Nu is het zaak om documenten via de DocHorizon API te laden en te laten verwerken. Daarvoor gebruiken we N8N.
N8N workflow en DocHorizon
Het is mooi om een API te hebben voor het inlezen van je document maar je wil dit natuurlijk kunnen zonder code te hoeven schrijven. Er zijn meerdere wegen die naar Rome leiden en N8N is er een van. Een andere optie is de flowbuilder van DocHorizon zelf. Daar doen we later een post over.
Hieronder zie je de flow voor het uitlezen van het contract dat we naar S3 hebben geupload. In dit geval is dat een S3 faciliteit van Digital Ocean maar het kan ook naar andere providers zoals whitesky.cloud (EU), Hetzner enz.
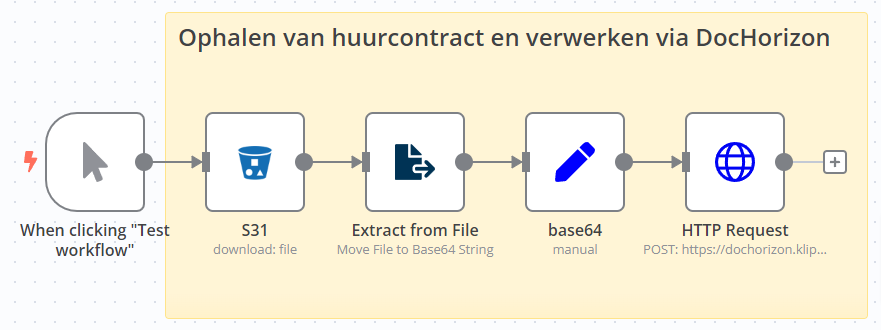
De stappen die we doorlopen zijn:
- ophalen document (en);
- omzetten naar Base64;
- data tijdelijk bewaren
- data POSTen naar DocHorizon URL.
De laatste stap leggen we nog iets meer in detail uit. Zie hieronder wat screenshots.
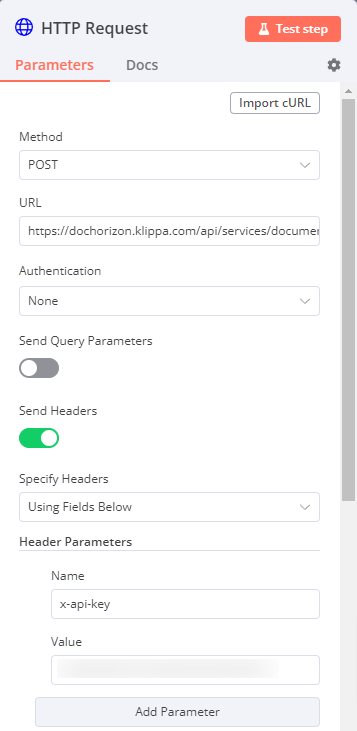
Het belangrijkste wat je moet doen is het configureren van de URL en de API key. De API key kun je zien in DocHorizon. Daarnaast kun je de URL ook in DocHorizon vinden.
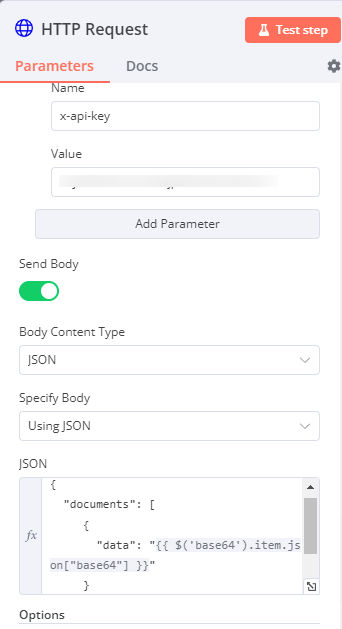
Het tweede deel waar je voor moet zorgen is dat het POST formaat correct gestructureerde JSON is. Dat zie je in het volgende screenshot.
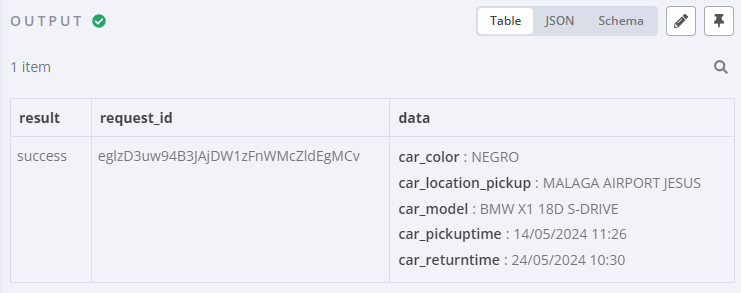
Als we nu de N8N workflow draaien dan krijgen we het volgende resultaat.
Moet je ook veel documenten verwerken en zit je te denken aan een maatwerk oplossing? Kijk eerst eens naar lowcode workflows voordat je dure maatwerk oplossingen gaat bouwen. Vaak kunnen we in een paar dagen al een mooi resultaat behalen.




